Introduction to Generative AI Concepts
What is generative AI?
- AI copies how humans act by learning from data and doing tasks on its own without being told what to do step by step.
- Generative AI describes a category of capabilities within AI to create original content.
- These capabilities including taking in natural language input and returning response in various formats such as natural language, image, code and more.
How do language models work?
- Over last decades, developments in the field of NLP have resulted in achieving LLMs.
- The development of language models has led to new ways to interact with applications and systems, such as through generative AI assistants and agents.
- Developments of language models include:
- Tokenization: enabling machines to read.
- Word embeddings: enabling machines to capture the relationship between words.
- Architectural developments: (changes in the design of language models) enabling them to capture word context.
Tokenization
- Since machines cannot understand text but numbers, we need to convert the text into numbers.
- One way of doing it is tokenization.
- Tokens are string which a mearning, usually representing a word.
- Tokenization, as the name suggest, means converting words into tokens, which are then converted into numbers.
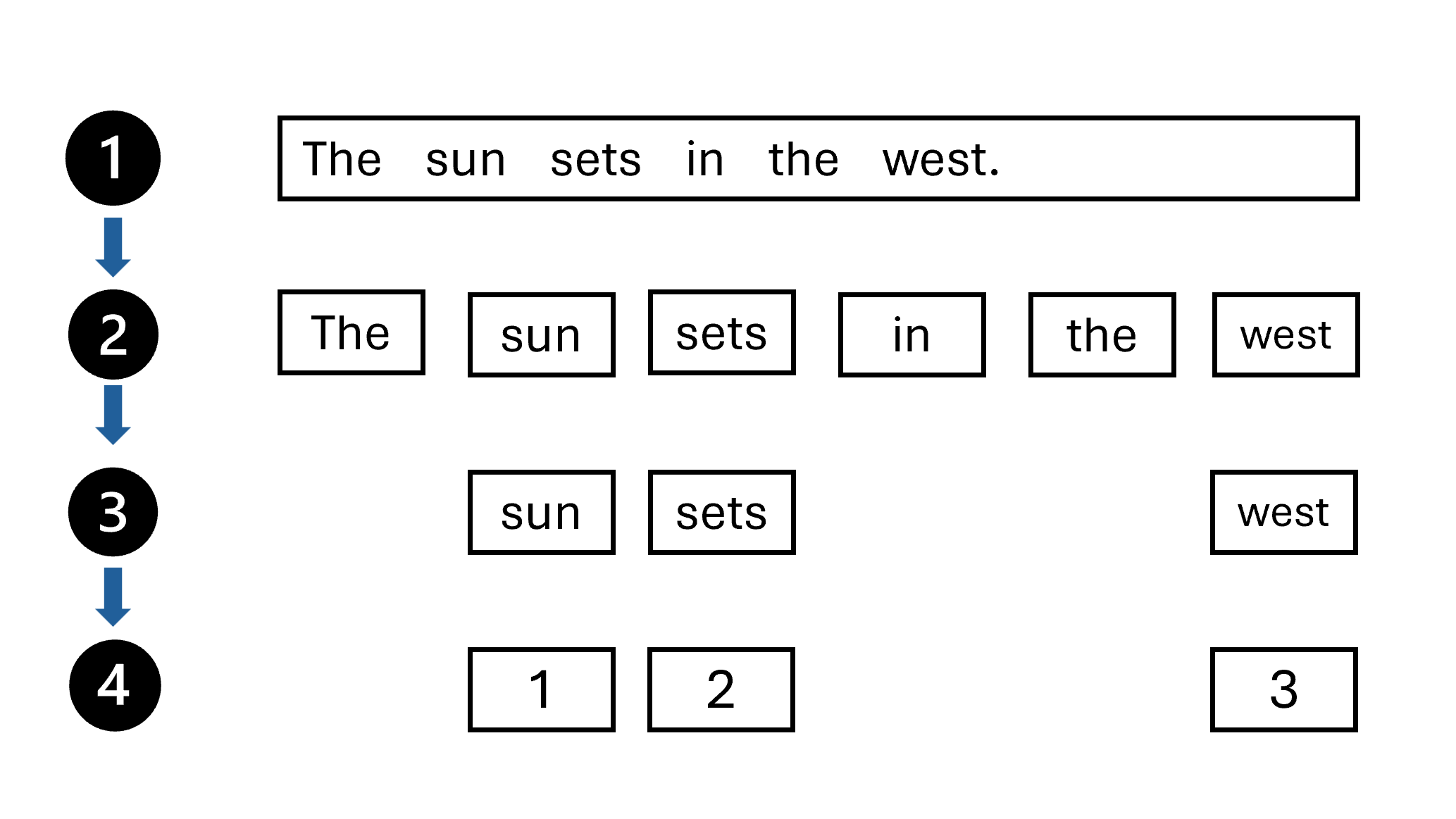
- Text to be tokenized.
- Split the text into chunks based on a rule. For example, it can be split into words.
- Next is 'Stop Work Removal'. Remove noisy words that does not add much meaning in the text such as
theanda. A list of such works is provided to remove them from text. - Assign a number to each unique token.
- Tokenization allowed for text to be labeled.
- As a result, statistical techniques could be used to let computers find patterns in the data instead of applying rule-based models.
Word Embeddings
-
One of the key concepts introduced by applying deep learning techniques to NLP is word embeddings.
-
It addresses the problem of not being able to define the semantic relationship between words.
-
Word embeddings are created during deep learning model training process.
-
During training, the model analyzes the co-occurrence patterns of words in sentences and learns to represent them as vectors.
-
A vector represents a path through a point in n-dimensional space, in other words, a line.
-
Semantic relationships are defined by how similar the angles of the lines are.
-
Since word embeddings represent words in a vector space, the relationship between words can be easily described and calculated.
-
To help the computer understand the meaning of words, we turn each word into a vector (embedding).
-
Each word’s vector is a list of numbers, like [10, 3, 1].
-
These numbers represent different features or meanings of the word, but we don’t define the features ourselves.
-
The model learns what these numbers mean during training by looking at how words are used in real sentences.
-
Vectors represent lines in multidimensional space, describing direction and distance along multiple axes.
-
A technique called cosine similarity is used to determine if two vectors have similar directions, regardless of distance.
Architectural developments
- The architecture of ML model decides how it handles data from input to training to prediction.
- One of the first breakthroughs in language model architecture was Recurrent Neural Networks (RNN).
- Understand text does not only mean understand individual word in isolation; but to understand the words around it to get the context in which the word is used.
Recurrent Neural Networks (RNN)
-
In RNN, each step takes an input, a hidden state, and also produces an output.
-
The hidden state serves as a memory of network.
-
It stores the output of the previous step and passes it as input to the next step.
-
Consider a following sentence,
"Vincent was a painter known for [MASK]". -
[Mask]represents the mission word that the model needs to predict. -
The RNN processes the sentence word by word:
- Step 1: Processes "Vincent"
- Step 2: Processes "was"
- Step 3: Processes "a"
- Step 4: Processes "painter"
- Step 5: Processes "known"
- Step 6: Processes "for"
-
At each step, the RNN updates its internal memory (hidden state) to capture the context up to that word.
-
Upon reaching
[MASK], the RNN utilizes its current hidden state, which encapsulates the context from all previous words, to predict the most probable word that fits. -
In this case, it might predict
"Vincent was a painter known for Starry Night".

Challenges with RNNs
- RNNs allow the context to be included when predicting the next word in relation to complete sentence.
- However, since the hidden state of RNN is updated with each token, the actual relevant information, may be lost.
- Since the hidden state has a limited size, the relevant information maybe deleted to make room for new and more recent information.
- As a human, when we read the sentence, we know that only certain words are essential to predict the last word.
Understand how transformers advance language models
- Model GenAI applications are made possible by utilizing Transformer Architecture.
- It introduced concepts that drastically improved a model's ability to understand and generate text.
- Different models have been trained using adaptations of the Transformer architecture to optimize for specific NLP tasks.
Understand Transformer architecture
- There are two main parts of a transformer:
- The encoder: Responsible to process the input sequence and create a representation that captures the context of each token. In simple words, converting the input sequence into a numeric representation.
- The decoder: Responsible to generate the output sequence by attending to the encoder's representation and predict the next token in the sequence.
- The most important innovations in Transformer architecture were positional encoding and multi-head attention.
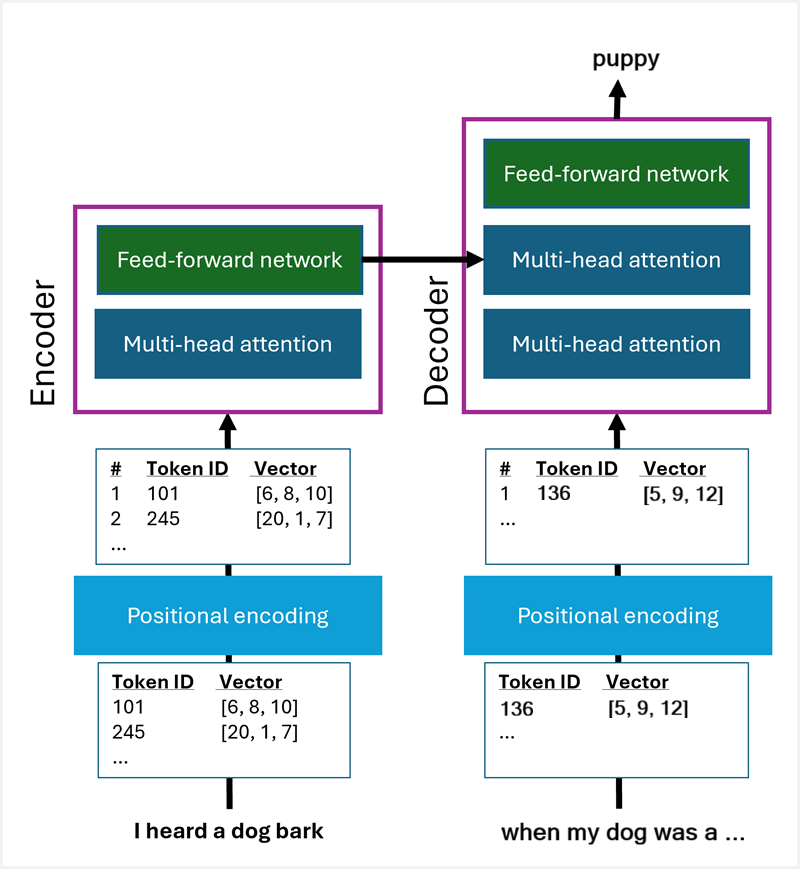
- In encoding layer, the input sequence is encoded with positional encoding.
- After this, multi-head attention is used to create a numeric representation.
- In the decoder layer, an incomplete output sequence is encoded in a similar way, that is by first passing it through the positional encoding and then multi-head attention.
- Further, the multi-head attention is used a second time to combine the output of the encoder and the output from the Decoder's multi-head attention.
- As a result, the output is generated.
Understand positional encoding
- Position of a word and order of a words are important to understand the meaning of a text.
- To include this information, transformers use positional encoding.
- Before transformers, language models used word embeddings to encode text into vectors.
- As mentioned that transformer architecture uses positional encoding to encode text into vectors.
- Positional Encoding is the sum of 'word embedding vectors' and 'positional vectors'.
- This makes sure that the encoded text includes information about meaning and position of word in a sentence.
- To encode the position of a word in a sentence, you could use a single number to represent the index value. For example:
| Token | Index value |
|---|---|
| The | 0 |
| work | 1 |
| of | 2 |
| William | 3 |
| Shakespeare | 4 |
| inspired | 5 |
| many | 6 |
| movies | 7 |
| ... | ... |
- The longer a text or sequence, the larger the index values may become.
- Though using unique values for each position in a text is a simple approach, the values would hold no meaning
Understand attention
-
The most important technique used by Transformers to process text is the use of attention instead of reoccurance.
-
RNNs are compute-intensive since they process words sequentially; however, transformers process each word independently in parallel using attention.
-
Attention is a mechanism used to map new information to learned information to understand what the new information entails.
-
Transformers use an attention function, where a new word is encoded (using positional encoding) and represented as a query.
-
The output of an encoded word is a key with an associated value.
-
To illustrate the three variables that are used by the attention function: the query, keys, and values, let's explore a simplified example.
-
Imagine encoding the sentence
Vincent van Gogh is a painter, known for his stunning and emotionally expressive artworks.When encoding the queryVincent van Gogh, the output may beVincent van Goghas the key withpainteras the associated value. -
The architecture stores keys and values in a table, which it can then use for future decoding:
| Keys | Values |
|---|---|
| Vincent Van Gogh | Painter |
| William Shakespeare | Playwright |
| Charles Dickens | Writer |
-
Whenever a new sentence is presented like
Shakespeare's work has influenced many movies, mostly thanks to his work as a .... -
The model can complete the sentence by taking
Shakespeareas the query and finding it in the table of keys and values. -
Shakespearethe query is closest toWilliam Shakespearethe key, and thus the associated valueplaywrightis presented as the output. -
To calculate the attention function, the query, keys, and values are all encoded to vectors.
-
The attention function then computes the scaled dot-product between the query vector and the keys vectors.
-
The dot-product calculates the angle between vectors representing tokens, with the product being larger when the vectors are more aligned.
-
The softmax function is used within the attention function.
-
Its output includes which keys are closest to the query.
-
The key with the highest probability is then selected, and the associated value is the output of the attention function.
-
The Transformer architecture uses multi-head attention, which means tokens are processed by the attention function several times in parallel.
-
By doing so, a word or sentence can be processed multiple times, in various ways, to extract different kinds of information from the sentence.
-
The Transformer architecture has allowed us to train models in a more efficient way.
-
Instead of processing each token in a sentence or sequence, attention allows a model to process tokens in parallel in various ways.
Understand differences in language models
- Thesedays developers dont need to train models from scratch to build GenAI application, but can use pretrained models.
- Some language models are open sourced; whereas others are offered in proprietary catalogs.
- Different models exists today.
- They differ by the data used to train them, or by the way they implement attention mechanism within their architecture.
Large and Small Language Models
- In general, language model can be considered in two categories: Large Language Model (LLMs) and Small Language Models (SLMs).
| Large Language Models (LLMs) | Small Language Models (SLMs) |
|---|---|
| LLMs are trained with vast quantities of text that represent a wide range of general subject matter. | SLMs are trained with smaller, more subject-focused datasets |
| When trained, LLMs have many billions (even trillions) of parameters (weights that can be applied to vector embeddings to calculate predicted token sequences). | Typically have fewer parameters than LLMs. |
| Able to exhibit comprehensive language generation capabilities in a wide range of conversational contexts. | This focused vocabulary makes them effective in specific conversational topics, but less effective at more general language generation. |
| Their large size can impact their performance and make them difficult to deploy locally on devices and computers. | The smaller size of SLMs can provide more options for deployment, including local deployment and on-premises computers; and makes them faster and easier to fine-tune. |
| Fine-tuning the model with more data to customize its subject expertise can be time-consuming, and expensive in terms of the compute power required to perform the extra training. | Fine-tuning can potentially be less time-consuming and expensive. |
Improve prompt results
- The quality of responses from GenAI assistants not only depends on language model used, but also on the prompt that user provides.
- The user can get a perfect response from GenAI assistant by providing explicit requirements in the prompt.
- Following are the ways to improve the response provided by GenAI.
- Starting with a specific goal.
- Providing a source to ground the response.
- Add context.
- Set clear expectations.
- Iterate based on previous prompts and responses to refine the result.
- For eg "Summarize the key considerations for adopting Copilot described in this document for a corporate executive. Format the summary as no more than six bullet points with a professional tone."
- In most cases, an agent does not just sends the prompt to the language model as is.
- It is usually augmented with,
- A system message that sets conditions and constraints for language model behavior like "You are a helpful assistant that responds in a cheerful, friendly manner."
- The conversational history.
- The current prompt, potentially optimized by the agent to reword it appropriately for the model or to add more grounding data to scope the response.
Create responsible generative AI solutions
- Microsoft's guidance is a practical roadmap for creating and using generative AI in a way that's ethical and responsible.
- Microsoft's responsible AI guidance for generative models involves a four-stage process:
- Predict problems
- Check for problems
- Fix problems
- User responsibly
- All these steps are based on 6 key responsible AI principles.
Responsible AI principles
-
It is important to consider the impact of software on users and society in general, especially when it includes AI.
-
This is due to the nature of how AI systems work and inform decisions because it is based on probabilistic models.
-
These probabilistic models are in turn dependent on the data with which they were trained.
-
The human like nature of AI helps making applications user friendly; however, it comes with a responsibility for the AI to make correct decisions.
-
There is a potential harm if the AI makes incorrect predictions or misuse of AI is a major concern.
-
Software engineers building AI enabled solutions should apply due considerations to mitigate these risks and ensure fairness and reliability.
-
Following are some core principles that Microsoft adopted for responsible AI
Fairness
- AI systems should treat all people fairly.
Reliability and Safety
- AI systems should perform reliably and safely.
- For example, consider an AI-based software system for an autonomous vehicle; or a machine learning model that diagnoses patient symptoms and recommends prescriptions.
- Unreliability in these kinds of system can result in substantial risk to human life.
Privacy and Security
- AI systems should be secure and respect privacy.
- The machine learning models on which AI systems are based rely on large volumes of data, which may contain personal details that must be kept private.
- Even after models are trained and the system is in production, they use new data to make predictions or take action that may be subject to privacy or security concerns; so appropriate safeguards to protect data and customer content must be implemented.
Inclusiveness
- AI systems should empower everyone and engage people. AI should bring benefits to all parts of society, regardless of physical ability, gender, sexual orientation, ethnicity, or other factors.
Transparency
- AI systems should be understandable. Users should be made fully aware of the purpose of the system, how it works, and what limitations may be expected.
Accountability
- People should be accountable for AI systems.
- Although many AI systems seem to operate autonomously, ultimately it's the responsibility of the developers who trained and validated the models they use, and defined the logic that bases decisions on model predictions to ensure that the overall system meets responsibility requirements.